$k$ plus proches voisins
(Cette première partie s'inspire fortement de l'introduction de Apprentissage statistique (Gérard Dreyfus et al.) - très bonne référence sur le sujet)On dispose d'un ensemble d'«objets», que l'on veut classer en deux catégories (disons rouge ou bleu).
À chaque objet est associé un vecteur de $\mathbb{R}^d$, représentant ses caractéristiques.
On parle de tâche d'apprentissage supervisé lorsque l'on dispose d'exemples d'objets pour lesquels on connaît la catégorie, et que l'on veut, pour un nouvel objet, décider à partir de ces exemples s'il appartient à la catégorie rouge ou bleu. (Pour un exemple de tâche d'apprentissage non-supervisé, voir la page sur les $k$-moyennes.)
La méthode des $k$-plus proches voisins est l'une des méthodes les plus simple pour y parvenir. Étant donné un nouvel objet $O$, on cherche parmi nos exemples les $k$ plus proches (où $k$ est un entier fixé). S'il y a une majorité d'objets rouges parmi eux, on décide que $O$ est rouge, sinon, on décide qu'il est bleu. On choisit $k$ impair afin d'éviter les cas d'égalité.
L'application ci-dessous permet de se familiariser avec cette méthode. On suppose ici que chaque objet est représenté par un point de $\mathbb{R}^2$. Les exemples sont figurés par les points rouges et bleus, qui dont la position est tirée au hasard selon des lois de probabilités $P_R$ et $P_B$. Lorsque l'on passe la souris sur l'image, les $k$ plus proches voisins du point sous le pointeur de souris sont calculés, et la catégorie de ce point est ainsi déterminée.
La deuxième image est une carte du plan, les zones rouges et bleues correspondant aux parties du plan où un nouvel objet arrivant serait classé dans la catégorie de couleur correspondante. Les pointillés désignent la frontière «idéale» entre les zones bleues et rouges - nous y reviendrons.
Je vous invite à manipuler l'application pour vous familiariser avec les résultats. En particulier, que peut-on remarquer sur les zones obtenues lorsque l'on fait varier $k$ ?
Erreur d'apprentissage : % | Erreur de généralisation ≈% | Borne théorique ≈%
Comment déterminer $k$ ?
C'est une question critique, dont va dépendre la qualité des résultats de la méthode. Vous avez du remarquer en manipulant le simulateur que des valeurs «trop grandes» ou «trop petites» ne donnaient pas des résultats satisfaisants.C'est ce que mesure l'erreur de généralisation : pour calculer celle-ci, une fois la carte obtenue, on tire un grand nombre de points selon la loi $P_R$ (i.e. de points qui «devraient» être rouges). On calcule la proportion de ces points qui tombent dans la zone bleue, et l'on fait de même en intervertissant les couleurs. Sur l'exemple ci-dessus par exemple, on obtient ≈% de points mal classés. Étant donné que l'on connaît les distributions $P_R$ et $P_B$ selon lesquelles les points rouges et bleus sont obtenus, il est possible de calculer également la borne théorique i.e. l'erreur qu'obtiendrait un classifieur optimal : il s'agit d'un classifieur bayésien, qui détermine pour chaque point du plan s'il est plus probable qu'il soit obtenu selon la loi $P_R$ (comme point rouge) ou selon la loi $P_B$ (comme point bleu). La frontière de ce classifieur est la ligne pointillée qui apparaît sur la figure.
Naïvement, on pourrait donc penser choisir le $k$ pour lequel l'erreur de généralisation est la plus petite possible.
Le souci est que, pour un problème réel, nous ne connaissons généralement pas les lois $P_R$ et $P_B$ régissant les positions des points rouges et bleus. Nous n'avons donc pas accès à l'erreur de généralisation (ni à la borne théorique) : nous ne pouvons pas générer de nouveaux exemples de points rouges et bleus pour tester la qualité de notre classifieur.
L'idée suivante est donc, plutôt que de tirer de nouveaux points, de tester la qualité du classifieur sur les points exemples eux-même. C'est la valeur correspondant à l'erreur d'apprentissage ci-dessus. Malheureusement, cela ne fonctionne pas. Si vous testez pour de petites valeurs de $k$, l'erreur d'apprentissage va être petite alors que l'on n'est pas nécessairement à l'optimum d'erreur de généralisation. Dans le cas extrème où $k=1$, tous les exemples sont correctement classés (il sont leur propre plus proche voisin !), alors que le classifieur généralise mal. On parle de phénomène de surraprentissage, ou sur-ajustement.
Les figures ci-dessous montrent des courbes typiques d'erreur d'apprentissage (bleu pour l'erreur de généralisation, rouge pour l'erreur d'apprentissage) en fonction de $k$. Le phénomène de sur-ajustement est visible pour de petites valeurs de $k$, pour lesquelles l'erreur d'apprentissage est très faible, alors que l'erreur de généralisation est grande.
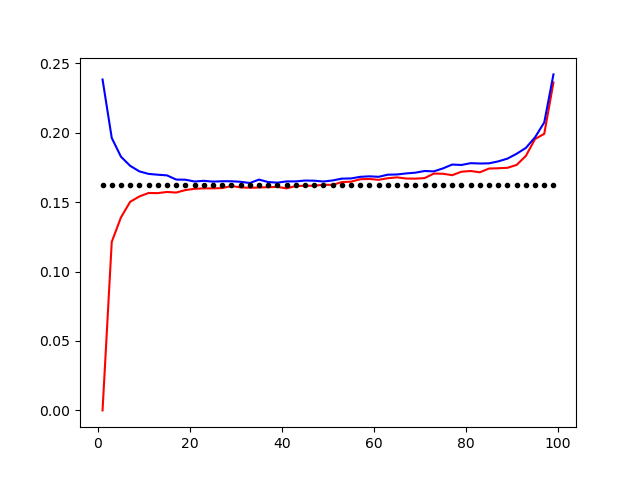
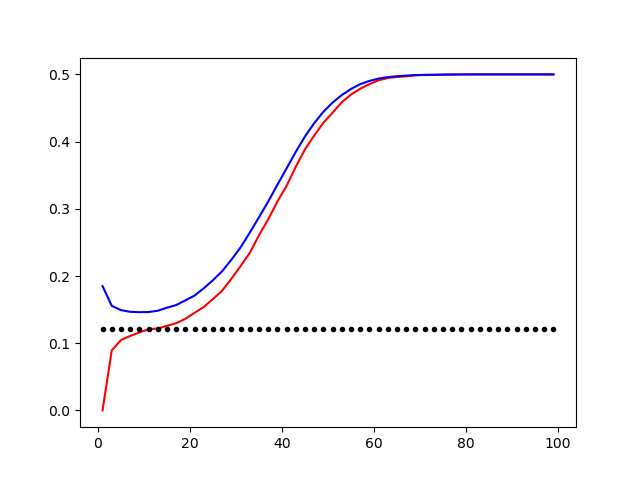
Courbes des taux d'erreur pour les distributions «gaussiennes rapprochées» (à gauche) et «radiales» (à droite). En rouge, l'erreur d'apprentissage. En bleu, l'erreur de généralisation. En pointillés, la borne théorique. On observe un sur-ajustement pour de petites valeurs de $k$.
En pratique, comme on dispose d'un nombre fini d'exemples, une solution est d'utiliser une validation croisée. On partitionne l'ensemble des exemples $\mathcal{E}$ en deux sous-ensembles : $\mathcal{E}_A$ et $\mathcal{E}_T$. On applique la méthode des $k$-moyennes uniquement à l'aide des exemples de $\mathcal{E}_A$, et on teste la qualité du classifieur obtenu à l'aide des exemples de $\mathcal{E}_T$ - ce qui permet d'obtenir une estimation empirique de l'erreur de généralisation, et de déterminer le meilleur paramètre $k$. Pour obtenir des résultats plus robustes, on peut répéter l'opération pour différentes partitions $(\mathcal{E}_A, \mathcal{E}_T)$.
Une application : reconnaissance optique de caractères
On dispose de 200 images de «0» et de «1», présentées ci-dessous. Nous allons utiliser la méthode des $k$-voisins pour obtenir un classifieur permettant du déterminer si une nouvelle image correspond à un «0» ou un «1». Nous choisissons 95 caractères de chaque comme exemples pour l'apprentissage (i.e. dans $\mathcal{E}_A$), et 5 de chaque pour tester la qualité du classifieur obtenu (ils sont donc dans $\mathcal{E}_T$, et sont grisés).| Exemple test |