Détection de collisions
On s'intéresse à cette page à quelques algorithmes de détection de collision, qui visent à détecter rapidement des intersections non-vides entre des «objets».Les applications sont nombreuses : géométrie algorithmique, simulations physiques, jeux videos, rendu d'environnements 2D ou 3D, SIG, planification de mouvement en robotique…
Cette page traite de quelques pistes algorithmes en 2D (qu'il serait intéressant d'adapter en 3D).
- I-Collision de deux objets
- II-Collision avec des objets statiques
- III-Collision d'objets en déplacement
I-Collision de deux objets
Le cas des rectangles avec axes alignés
Considérons deux rectangles dont les côtés sont alignés avec les axes. Une formule booléenne simple permet alors de tester s'ils s'intersectent $$\mathbf{non(}x^1_{min} > x^2_{max}\ \mathbf{ou}\ x^2_{min} > x^1_{max}\ \mathbf{ou}\ y^1_{min} > y^2_{max}\ \mathbf{ou}\ y^2_{min} > y^2_{max}\mathbf{)}$$ Le $x^1_{min} > x^2_{max}$ tranduisant par exemple le fait que le premier rectangle est strictement à droite du second.Dans la figure suivante, vous pouvez cliquer sur un rectangle pour le déplacer et observer les différentes configurations possibles.
Le cas des polygones convexes
C'est tout de suite plus délicat.Notons $P_1$ et $P_2$ les deux polygones. Voici deux algorithmes simples et tentants mais … faux !
- Renvoyer vrai si et seulement si au moins un segment de $P_1$ intersecte un segment de $P_2$. (1)
- Renvoyer vrai si et seulement si au moins un sommet de $P_1$ est à l'intérieur de $P_2$ ou l'inverse. (2)
L'implémentation la plus simple à ma connaissance repose sur le théorème suivant - un cas particulier de séparation des convexes.
On considère deux polygones convexes $P_1$ et $P_2$.
Leur intersection est vide si et seulement si il existe un côté $C$ de l'un des polygones $P$ tel que
Si les polygones convexes sont décrits par la liste de leurs
sommets successifs dans le sens horaire, tous ses sommets
sont alors à gauche de chaque droite orientée reliant des sommets
successifs. Il suffit alors de tester les tous les sommets
de l'autre polygone sont strictement à droite. On obtient
alors un algorithme de complexité $O(n_1n_2)$ pour tester
la collision, où $n_1$ et $n_2$ sont les nombres de
sommets respectifs de $P_1$ et $P_2$.
- tous les sommets de $P$ sont dans l'un des demi-plans délimités par la droite prolongeant $P$ (au sens large)
- tous les sommets de l'autre polygone sont dans l'autre demi-plan (au sens strict)
À noter qu'il est possible de faire mieux et de généraliser à des polygones non convexes les découpant en polynomes convexes - par exemple en utilisant des algorithmes par balayage.
Ce problème peut être résolu en $O(n+m)$ par une méthode plus subtile (cf Separation of Two Monotone Polygons in Linear Time, Toussaint & Gindy)
Dans le cas où l'on doit tester des collisions entre de nombreux objets potentiellement éloignés, il est pertinent de précalculer pour chaque objet sa boîte englobante (ou bounding box, le plus petit rectangle dont les côtés sont alignés avec les axes et qui contiennent l'objet), et de tester la collision de ses boîtes en utilisant la méthode décrite pour les rectangles ci-dessus avant de tester la collision des polygones (ce qui devient inutile si les boîtes englobantes ne s'intersectent pas).
Beaucoup de questions intéressantes peuvent se poser sur l'implémentation efficace d'autres types d'objets, que ce soit en 2D ou en 3D. Cette page recense de nombreux articles concernant ce sujet.
II-Détection de collision d'un objet avec des obstacles statiques
Considérons un ensemble de $N$ obstacles dans le plan, et un objet $o$ dont on souhaite savoir s'il est en collision au moins l'un des obstables.L'algorithme naïf consiste à tester la collision de $o$ avec chacun des $N$ obstacles. On peut faire mieux que cela en organisant les obstacles dans une structure précalculée prenant en compte leur agencement spatial.
L'application suivante permet de comparer les résultats obtenus par l'algorithme naïf et trois autres algorithmes qui sont présentés à la suite.
- Déplacer la souris pour faire bouger l'objet $o$. Les obstacles dont la collision est effectivement testée avec $o$ apparaissent en orange (s'ils ne sont pas en collision avec $o$) et rouge (s'il l'intersectent). Si le coût du test de collision est important, il faut donc privilégier un algorithme qui limite le nombre d'obstacles oranges. Le temps d'exécution est donné à titre indicatif : le code est largement optimisable.
- Cliquer pour rajouter un obstacle ce qui permet, partant d'un petit nombre d'obstacles, d'observer la formation des Quadtrees ou des AABB Trees.
Naïf
Collisions testées :
Collisions réelles :
Temps d'exécution :
Collisions testées :
Collisions réelles :
Temps d'exécution :
Dichotomie
Collisions testées :
Collisions réelles :
Temps d'exécution :
Collisions testées :
Collisions réelles :
Temps d'exécution :
Quadtree
Profondeur :
Noeuds dans l'arbre :
Noeuds explorés :
Collisions testées :
Collisions réelles :
Temps d'exécution :
Profondeur :
Noeuds dans l'arbre :
Noeuds explorés :
Collisions testées :
Collisions réelles :
Temps d'exécution :
AABB Tree
Profondeur :
Noeuds dans l'arbre :
Noeuds explorés :
Collisions testées :
Collisions réelles :
Temps d'exécution :
Profondeur :
Noeuds dans l'arbre :
Noeuds explorés :
Collisions testées :
Collisions réelles :
Temps d'exécution :
Dichotomie sur les abscisses, puis balayage local
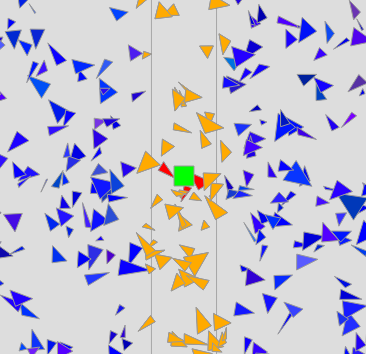 C'est l'idée la plus simple.
C'est l'idée la plus simple.
On détermine les abscisses minimales $x_i^{min}$ et maximales $x_i^{max}$ de chaque obstacle $i$, et l'on note $R_i=\frac{x_i^{max}-x_i^{min}}{2}$ son «rayon horizontal», et $R=\max_i R_i$ le maximum de ces rayons.
On précalcule alors une liste $l$ contenant les obstacles classés par «abscisses moyennes» $m_i=\frac{x_i^{min}+x_i^{max}}{2}$ croissantes.
On définit de même $R_o$ la largeur de l'objet $o$, ainsi que $m_o$.
On recherche alors par dichotomie la position où $o$ devrait se trouver dans la liste $l$.
On balaye alors cette liste
- vers la gauche tant que $x_o^{min}\leq m_i+R$ (après quoi on est assuré que l'objet de peut plus intersecter d'obstacle - son abscisse minimale étant trop grande)
- vers la droite tant que $x_o^{max}\geq m_i-R$ (symétriquement)
On restreint donc le test d'intersection à des obstacles situés dans une bande verticale centrée sur l'objet.
On pourrait penser à effectuer les mêmes opérations sur une bande horizontale et intersecter avec la bande verticale d'une façon ou d'une autre, mais c'est une mauvaise idée : le coût supplémentaire sera toujours supérieur au coût des tests de collisions (avec boîte englobante) des objets de la seule bande verticale. On verra en revanche une idée proche en œuvre pour les calculs d'intersections d'objets en mouvement.
AABB Tree
(Aligned Axis Bounding Boxes)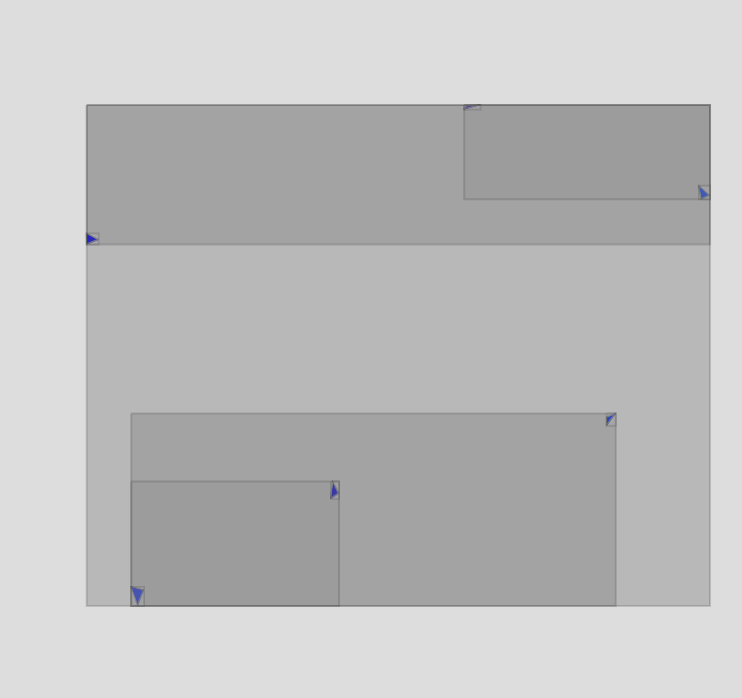
Les arbres AABB généralisent l'idée des boîtes englobantes présentées ci-dessus, en hiérarchisant les boîtes sous formes d'un arbre binaire : un sommet est une boîte qui englobe un obstacle (le sommet est alors une feuille) ou deux autres sommets.
Lorsque l'on recherche quels obstacles peuvent être intersectés par un objet $o$, on part de la racine et n'explore que les sommets dont la boîte intersecte $o$.
Il y a plusieurs manières de construire un tel arbre
- Les approches par lots (batch) nécessitent de connaître tous les obstacles dès le départ. On peut alors construire l'arbre
- de haut en bas (top down) : à partir d'une boîte racine englobant tous les obstacles, on sépare l'ensemble en deux sous-ensembles, dont les boîtes englobantes seront les fils de la racine, puis on poursuit récursivement.
- de bas en haut (bottom up) à partir des futures feuilles de l'arbre (les boîtes englobantes des obstacles individuels), on les regroupe récursivement.
Pour tester la construction, sélectionnez un petit nombre d'obstacles de départ dans l'application, puis cliquez sur la figure pour insérer de nouveaux obstacles.
En pratique, les implémentations les plus efficaces en mode batch sont des approches top down utilisant la mesure SAH.
Pour plus d'informations, consultez par exemple la page Wikipedia anglophone sur les hiérarchies de boîtes englobantes. Voir également la page sur le regroupement hiérarchique - un problème ressemblant.
Quadtree
 Les Quadtrees (Arbres Quaternaires) sont une méthode classique de partitionnement récursif d'un espace de dimension 2 (ils se généralisent par les Octrees en
dimension 3).
Partant d'un carré à partionner, la racine de
l'arbre représente le carré en entier. On
découpe ce carré initial en quatre carrés, qui
seront représentés par les fils de la racine,
et ainsi de suite récursivement, jusqu'à ce
qu'une profondeur donnée soit atteinte.
Les Quadtrees (Arbres Quaternaires) sont une méthode classique de partitionnement récursif d'un espace de dimension 2 (ils se généralisent par les Octrees en
dimension 3).
Partant d'un carré à partionner, la racine de
l'arbre représente le carré en entier. On
découpe ce carré initial en quatre carrés, qui
seront représentés par les fils de la racine,
et ainsi de suite récursivement, jusqu'à ce
qu'une profondeur donnée soit atteinte. Chaque feuille contient une liste de pointeurs vers les obstacles que son carré intersecte.
Chaque sommet de l'arbre aura zéro ou quatre fils, et l'on peut décider de construire un arbre complet, ou au contraire d'arrêter de subdiviser un carré lorsqu'il n'intersecte aucun obstacle.
Le test de collision avec un objet $o$ consiste alors comme pour les arbres AABB à partir de la racine et à n'explorer que les fils représentant des carrés qui intersectent $o$.
Voir également la page sur les arbres kd, une autre méthode de partionnement spatial adaptée à la recherche du plus proche voisin d'un point parmi un ensemble de points fixés.
III-Intersection d'objets en déplacement
Méthodes a posteriori
On s'intéresse pour finir à des tests de collisions deux à deux d'un ensemble d'objets en déplacement. On considèrera dans un premier temps des simulations à temps discret (de type «éléments finis») impliquant des particules circulaires se déplaçant dans le plan à vitesse uniforme et rebondissant sur les bords de la figure.Il y a deux nouveaux enjeux par rapport à la section précédente, où l'on testait l'intersection d'un unique objet avec un certain nombre d'obstacles statiques.
- La structure permettant les tests de collisions peut-elle être mise à jour rapidement pour tenir compte des variations de positions des objets à chaque pas de temps ?
- Permet-elle de tester rapidement les collisions entre tous les couples d'objets ?
L'application ci-dessous implémente quelques algorithmes et permet de comparer leur vitesse :
- la méthode naïve, pour laquelle les collisions de tous les couples de particules sont testées à chaque pas de temps
- un Quadtree (où à chaque pas de temps, chaque particule est enlevée puis réinsérée dans l'arbre). En pratique, cette structure paraît peu adaptée, la suppression/réinsertion étant trop coûteuse.
- une liste des objets triée par abscisses croissantes permettant d'adapter la méthode de balayage local ci-dessus (en utilisant une fenêtre glissante pour détecter les couples de particules qui sont susceptibles d'être en collision). La mise à jour du tableau des abscisses d'un temps discret au suivant est faite en utilisant un tri par insertion - très efficaces sur les listes déjà «presque triées».
- une méthode dédiée, appelée tableaux glissants dans le simulateur ci-dessous. On note $\mathcal{E}=\{P_1\cdots P_n\}$ l'ensemble des particules, chacune ayant un rectangle englobant
$[a_i,b_i]\times [c_i,d_i]$.
Au début de la simulation, on place tous les $a_i$ et $b_i$ dans un unique tableautxtrié par ordre croissant. Un parcours linéaire detxpermet alors de déterminer l'ensemble $S_x$ des couples de particules $(P_i,P_j)$ tels que les intervalles d'abscisses $[a_i,b_i]$ et $[a_j,b_j]$ se chevauchent. On procède de la même façon pour les intervalles $[c_i,d_i]$ pour calculer l'ensemble $S_y$ correspondant pour les ordonnées. On obtient alors l'ensemble $S=S_x\cap S_y$ des couples de particules dont les boîtes englobantes s'intersectent, à partir duquel on effectue les tests de collisions effectifs.
Lors d'une itération temporelle de la simulation, chaque particule $P_i$ est légèrement déplacé ainsi que sa boîte englobante $[a_i,b_i]\times[c_i,d_i]$. On considère itérativement chaque particule $P_i$ et on note $[a'_i,b'_i]\times[c'_i,d'_i]$ sa nouvelle boîte englobante après déplacement. Danstx, on remplace $a_i$ et $b_i$ par $a'_i$ et $b'_i$, puis on déplace ces éléments en les permutant itérativement avec leurs voisins pour rétablir la monotonie detxtout en mettant à jour $S_x$. On procède de même pour $S_y$. On obtient finalement un nouvel ensemble $S$ de couples de particules dont les boîtes englobantes s'intersectent à partir duquel on effectue à nouveau les tests de collisions effectifs.
C'est en pratique la méthode la plus efficace sur notre problème, un peu devant la méthode utilisant seulement la liste triée par abscisses moyennes croissantes.
Modèle physique : Test de collisions sans déviation Collisions élastiques Collisions élastiques avec gravité
Méthode de simulation :Méthode naïve Liste par abscisses croissantes Tableaux Glissant Quad Tree ( )
A Priori
Choc élastique
Une fois les collisions détectées (on parle de détection a posteriori), on peut utiliser un modèle physique, par exemple de choc élastique pour dévier les particules.C'est ce qui est fait dans l'application ci-dessus (avec des chocs élastiques de type «boules de billard» - où l'interaction entre deux particules se traduit par des forces contenues dans la droite passant par leur centre - mais que l'on pourrait adapter pour simuler d'autres types d'interactions).
On peut par exemple y observer la diffusion de particules de deux couleurs, ou le trajet de la particule orange individualisée. On peut également rajouter une force gravitationnelle, pour observer la répartition des particules selon l'altitude, etc.
Le problème des approches a posteri et que la collision est détectée trop tard, ce qui peut entraîner des aberrations (ici les couples de particules qui restent «collées» entre elles). On peut même rater intégralement une collision si une particule rapide en «traverse» une autre entre deux pas de temps successifs.
Les approches a posteriori permettent cependant de mettre en place plus facilement ce type de simulations que les méthodes a priori, qui ne fonctionnent pas avec un pas de temps mais consistent à prévoir le moment exact de la prochaine collision à partir de l'ensemble des paramètres (position et vitesse) des particules, et à faire évoluer le système d'une collision à la suivante.
Méthode a priori
On se replace dans le cas sans gravité.Connaissant les positions et vitesses de l'ensemble des particules, on peut analytiquement déterminer la prochaine collision de chacune d'entre elles avec une paroi ou avec une autre particule. C'est très simple pour une paroi, et étant donné deux particules de positions respectives $p_1$ et $p_2$ et de vitesses $v_1$ et $v_2$, et de rayon $r$, on peut déterminer s'il existe le plus petit temps $t>0$ tel que $\|(p_1+tv_1)-(p_2+tv_2)\| = 2r$ - il s'agit en fait de résoudre une équation de degré 2. (Si l'on change le modèle physique, on risque de tomber sur une équation qui n'est pas résoluble analytiquement - et l'on peut donc avoir recours à des méthodes approchées).
On cherche le minimum de tous ces temps pour l'ensemble des particules, et l'on obtient donc le temps du prochain «évènement» se produisant pour l'ensemble des particules.
On peut alors «avancer» directement la simulation jusqu'à ce temps - qui est le temps exact $t_{min}$ de la prochaine collision - sans utiliser une méthode de type éléments finis.
La collision est donc gérée au temps exact où elle se produit, ce qui évite les problèmes des approches a posteriori.
Les calculs étant lourds, on gagne à stocker le prochain évènement pour chaque boule dans une file de priorité - de façon à pouvoir extraire rapidement la ou les boules $b_1$ (et $b_2$) concernées par la prochaine collision. Après une collision, on recalcule uniquement les temps de prochaine collision de $b_1$ (et $b_2$) et des particules dont le prochain évènement était une collision avec $b_1$ (ou $b_2$) - la priorité des autres particules étant simplement diminuée de $t_{min}$