Il est conseillé, avant de lire cette page, de se familiariser avec les structures de liste et de tableau.
Cette page traite des table de hachage, une structure de données permettant d'implémenter les structures abstraites d'ensembles et de dictionnaires. Il sera rapidement question de l'implémentation de ces structures en Python.
Ensembles, dictionnaires, et implémentation naïve
Structures abstraites
-
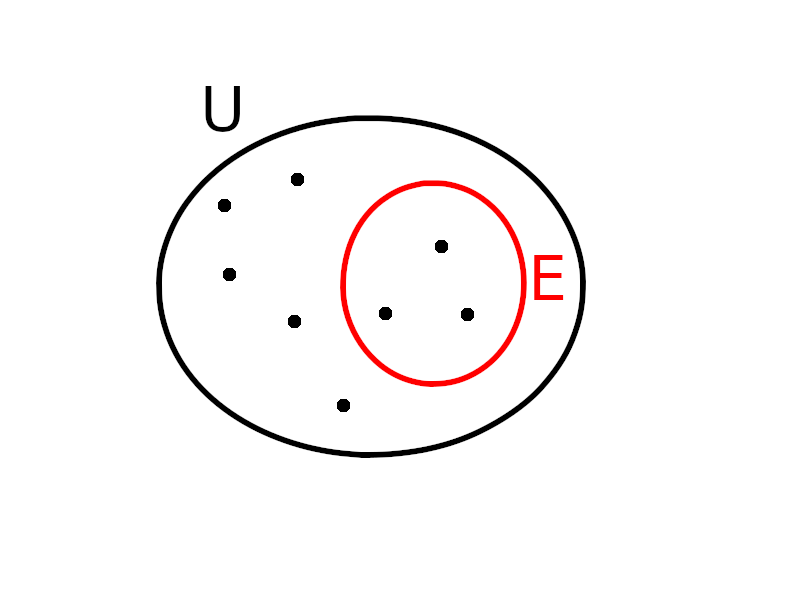
Un ensemble $E$ (sur un ensemble
mathématique d'objets $U$ - pour univers)
est une structure de données permettant de
représenter des parties de $U$, i.e. sur laquelle
on dispose des opérations suivantes :
- rechercher si un élément de $U$ est dans $E$ ou pas;
- insérer un élément de $U$ dans $E$;
- supprimer un élément de $E$.
-
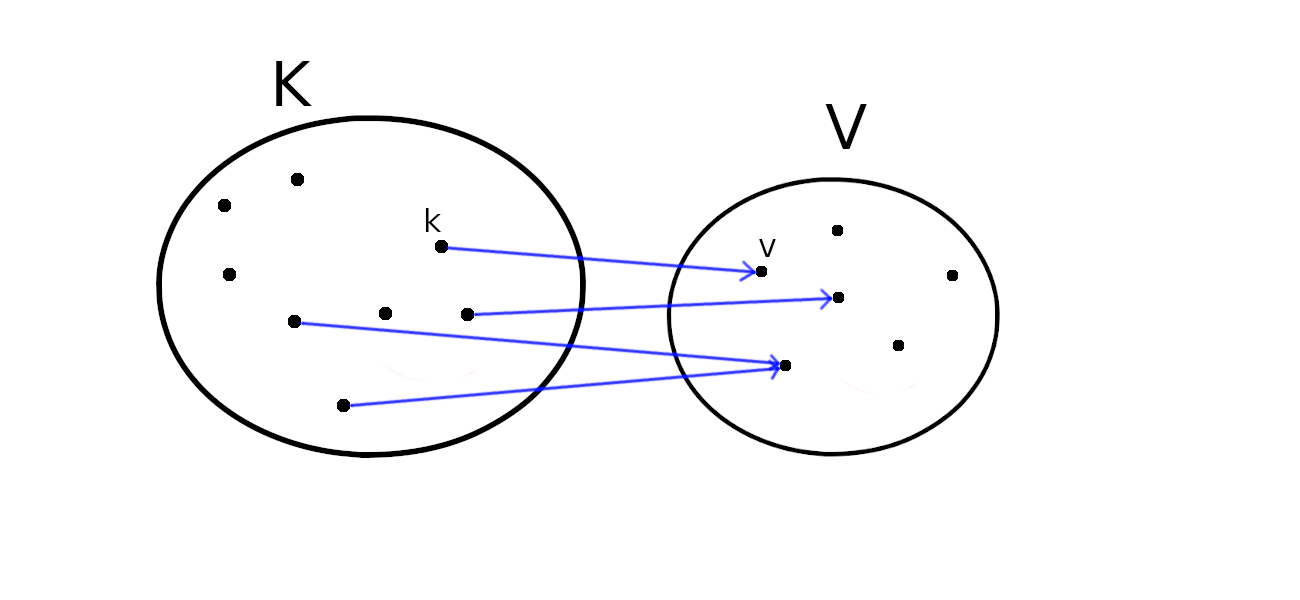
Un dictionnaire $D$ sur un ensemble de clés
$K$ et un ensemble de valeurs
$V$ est une extension de la structure de tableau. Intuitivement,
on peut voir cela comme un tableau contenant des
éléments de l'ensemble $V$, qui au
lieu d'être indicé par l'ensemble des entiers de
zéro à la longueur du tableau moins un, est indicé
par des clés de l'ensemble $K$. Si $k\in K$ est
une clef apparaissant dans le dictionnaire $D$,
$D[k]$ sera donc la valeur $v\in V$ correspondant
à la clé $k$. On parlera d'association clé/valeur $k\rightarrow v$ dans la suite. Mathématiquement, un dictionnaire peut être vu comme une application partielle de $K$ dans $V$.
Les opérations dont on a typiquement besoin sont :- rechercher si une clé apparait dans la table, et quelle est la valeur correspondante;
- insérer une valeur correspondant à une clé dans la table;
- suppprimer une valeur correspondant à une clé dans la table.
Exemples en Python
Pour se familiariser avec ces structures, on peut par exemple regarder la façon dont elles fonctionnent en Python.Ensembles (set)
>>> e = {'objet1', 'objet2'}
>>> type(e)
<class 'set'>
>>> 'objet1' in e #rechercher
True
>>> 'objet3' in e
False
>>> e.add('objet3') #insérer
>>> e
{'objet2', 'objet3', 'objet1'}
>>> e.add('objet3') #insérer à nouveau
>>> e
{'objet2', 'objet3', 'objet1'}
>>> e.remove('objet2') #supprimer
>>> e
{'objet3', 'objet1'}
Dictionnaires (dict)
>>> d = {'clef1':'valeur1', 'clef2':'valeur2', 'clef3':'valeur3'}
>>> type(d)
<class 'dict'>
>>> d['clef1'] #rechercher
'valeur1'
>>> d['clef4']
KeyError: 'clef4'
>>> d['clef2'] = 'nouvellevaleur' #insérer
>>> d
{'clef3': 'valeur3', 'clef2': 'nouvellevaleur', 'clef1': 'valeur1'}
>>> del d['clef2'] #supprimer
>>> d
{'clef3': 'valeur3', 'clef1': 'valeur1'}
Dans la suite, il sera principalement question des ensembles.
Tentative d'implémentation naïve du type abstrait ensemble
On pourrait être tenté d'implémenter un ensemble par l'une des structures étudiées dans la page sur les listes et tableaux. Un ensemble $E$ serait simplement représenté par un tableau de ses éléments, une liste chaînée de ses éléments, ou un tableau dynamique de ses éléments. On obtient alors les complexités suivantes pour les opérations élémentaires :| Tableau | Liste simplement chaînée | Tableau dynamique | |
|---|---|---|---|
| Recherche | $O(n)$ | $O(n)$ | $O(n)$ |
| Insertion | $O(n)$ | $O(1)$ | $O(1)$* |
| Suppression | $O(n)$ | $O(n)$ | $O(1)$* |
On peut également penser à utiliser des tableaux triés (cela nécessite de définir une relation d'ordre sur l'ensemble des éléments que l'on considère). Cela permet d'accélérer la recherche en utilisant une dichotomie, mais pas l'insertion et la suppression.
| Tableau trié | |
|---|---|
| Recherche | $O(\log(n))$ |
| Insertion | $O(n)$ |
| Suppression | $O(n)$ |
Aucune solution n'est totalement satisfaisant - idéalement, on voudrait atteindre une complexité $O(1)$ pour les trois opérations élémentaires. Les tables de hachage vont permettre de faire cela.
Un petit exercice auquel réfléchir avant de poursuivre vers les tables de hachages : imaginez que vous ayez à disposition 128 tiroirs numérotés, dans lesquels vous allez devoir ranger des fiches (sur des livres par exemple) qui vont vous parvenir. Chaque fiche a pour entête le titre du livre. Quelle stratégie adopter pour ranger les fiches qui vont vous parvenir dans les différents tiroirs - de façon à pouvoir les retrouver rapidement :
- si l'on peut mettre plusieurs fiches par tiroir ?
- si l'on ne peut mettre qu'une fiche par tiroir ?
Tables de hachage
Principe général
Les tables de hachages sont une solution relativement simple, rapide, et par conséquent fréquemment utilisée pour implémenter les structures d'ensemble et de dictionnaires.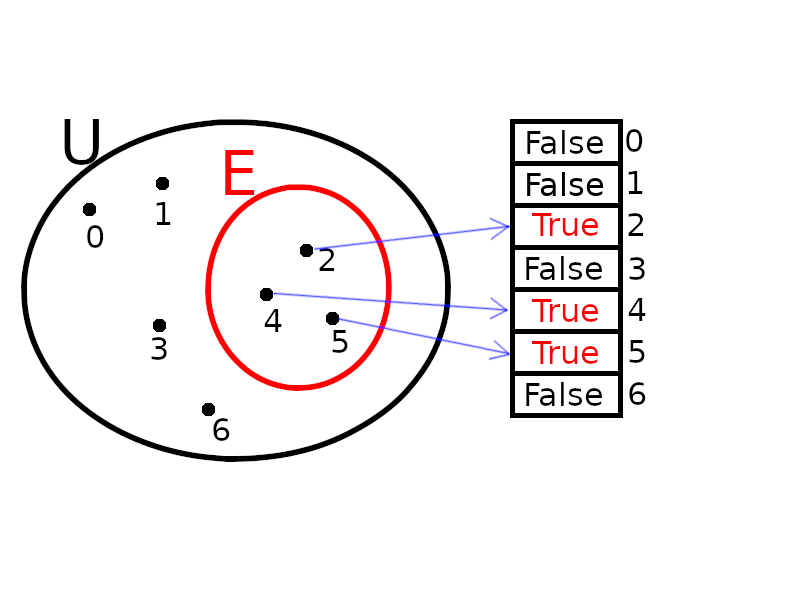 Pour faire un pas vers les tables de hachage, supposons
que nous souhaitions implémenter un ensemble $E$ sur l'univers
$U=\{0 \cdots N-1\}$ (où $N\in\mathbb{N}^*$). Pour ce faire, on peut utiliser un simple tableau
Pour faire un pas vers les tables de hachage, supposons
que nous souhaitions implémenter un ensemble $E$ sur l'univers
$U=\{0 \cdots N-1\}$ (où $N\in\mathbb{N}^*$). Pour ce faire, on peut utiliser un simple tableau t de taille N, dont les cases (appelées alvéoles) sont initialisées à une valeur conventionnelle (par exemple False en Python), et où le fait que $e\in E$ est représenté par le fait que t[e] == True. Ainsi, si $N=4$ et $U=\{0,1,2,3\}$, l'ensemble $\left\{0,\ 2\right\}$ sera représenté par le tableau [True, False, True, False]. On parle d'adressage direct.
Code Python pour l'implémentation naïve d'un ensemble par adressage direct
def rechercher(e, t):
"""teste si e appartient à l'ensemble t"""
return t[e]
def inserer(e, t):
"""ajoute e à l'ensemble t"""
t[e] = True
def supprimer(e, t):
"""supprime e de l'ensemble t"""
t[e] = False
Ces idées peuvent être facilement adaptées pour implémenter un dictionnaire dont l'ensemble des clés $K$ est de la forme $\{0 \cdots N-1\}$ (l'ensemble des valeurs $V$ étant quelconque), à l'aide d'un tableau
t de longueur $N$ vérifiant t[k]==None si la clé $k$ est absente du dictionnaire, et t[k]==v si
l'association $k\rightarrow v$ y apparaît.
Code Python pour l'implémentation naïve d'un dictionnaire par adressage direct
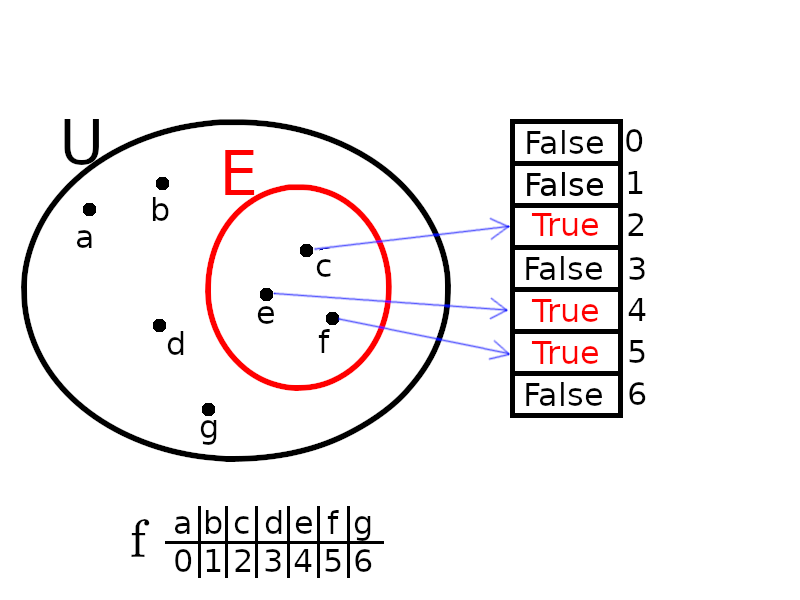
Et si l'univers $U$ ou l'ensemble des clés $K$ n'est pas de la forme $\{0 \cdots N-1\}$, mais par exemple l'ensemble des chaînes de caractères de longueur au plus 4 ? Pas de panique, il suffit de disposer d'une fonction $f$ transformant bijectivement une telle chaîne de caractères en un entier compris entre 0 et $N-1$ (où $N=|U|$), et de remplacer
def valeur(c, t):
"""renvoie la valeur correspondante à la clé c dans le dictionnaire t"""
return t[c]
def inserer(c, v, t):
"""insere le couple clé/valeur c -> v dans le dictionnaire t"""
t[c] = v
def supprimer(c, t):
"""supprime l'association de clé c du dictionnaire t"""
t[c] = None
c par f(c) dans les fonctions ci-dessus. (Chaque chaîne de caractère $c$ est donc codée par un entier $f(c)$.)
Problème : $|U|$ peut être grand (si l'on considère l'ensemble des chaînes constituées d'au plus 4 caractères choisis parmi les 52 minuscules et majuscules, on a déjà $|U|=7\;454\;981$), voire … infini ! (Si $U$ est l'ensemble des chaînes de caractères par exemple.) Même si $U$ est fini, utiliser un tableau de taille $|U|$ risque d'être infaisable en pratique, ou en tout cas de conduire à une utilisation de la mémoire trop importante, notamment si le nombre d'éléménts destinés à être insérés dans l'ensemble est très petit devant $|U|$.
L'idée des tables de hachage est de renoncer à utiliser une fonction bijective entre $U$ et $\{0 \cdots |U|-1\}$, et de se contenter d'une application de $U$ dans $\{0 \cdots n-1\}$, où $n$ est un entier.
En pratique, on se donne une fonction $h$ de $U$ dans $\mathbb{Z}$, appelée fonction de hachage. En Python, il existe une fonction
hash effectuant
cette opération pour les types usuels. Ci-dessous, quelques exemples obtenus avec CPython sur une machine 64 bits pour des chaînes de caractères (pour lesquelles hash renvoie une valeur entre $-2^{63}$ et $2^{63}-1$, différente de $-2$, cf infra.)
>>> hash('a')
-8768628398929236927
>>> hash('b')
1854369956633301891
>>> hash('bonjour')
-1354370923964979015
>>> hash('test')
-242861792972876742
True ou False : lorsque l'on recherche un élément, on pourra bien vérifier que c'est lui qui est présent dans l'alvéole, et non pas un autre élément qui aurait été haché dans la même alvéole. Les cases non-utilisées contiennent une valeur conventionnelle, par exemple None.
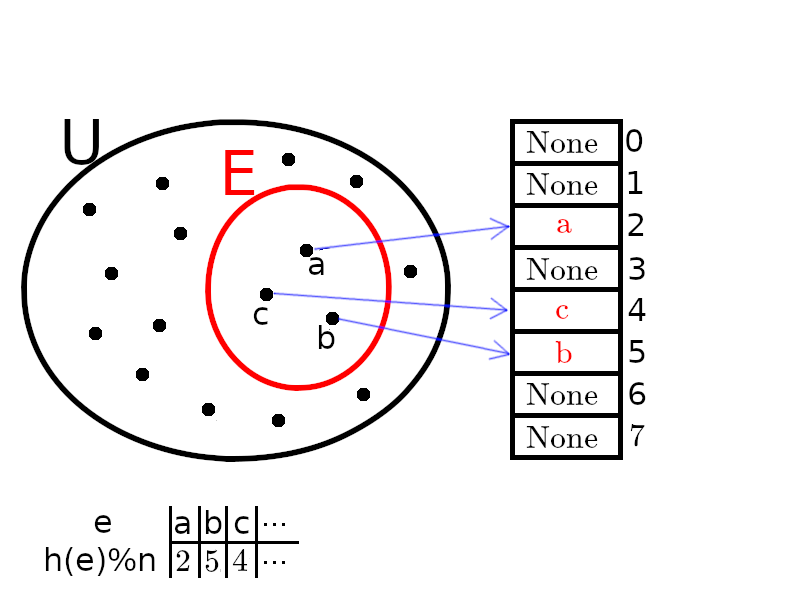
L'application ci-dessous permet de tester une implémentation d'un ensemble de chaînes de caractères - en modifiant la taille du tableau ainsi que la fonction de hachage. La première fonction de hachage proposée est une fonction naïve associant à chaque mot le code ASCII de sa première lettre (translaté de façon à ce que les mots commençant par «a» soient envoyés sur 0). Les mots proposés sont issus d'un dictionnaire d'environ $20\;000$ mots français (disponible ici).
Table de hachage implémentant un ensemble
Ajouter :
| Mot $k$ | ||||||
| $h(k)$ | ||||||
| $h(k)\%n$ |
Ajouter : ($h(k)=$ _, $h(k)\%n=$_)
Ajouter
Supprimer : cliquer sur le mot à supprimer.
Nombre de mots : | Taux de remplissage :
Collisions
Le fait que la fonction $h$ ne soit pas injective (ni à plus forte raison l'application $e\mapsto h(e)\% n$) conduit à des collisions : deux éléments distinctes peuvent être hachés sur la même alvéole.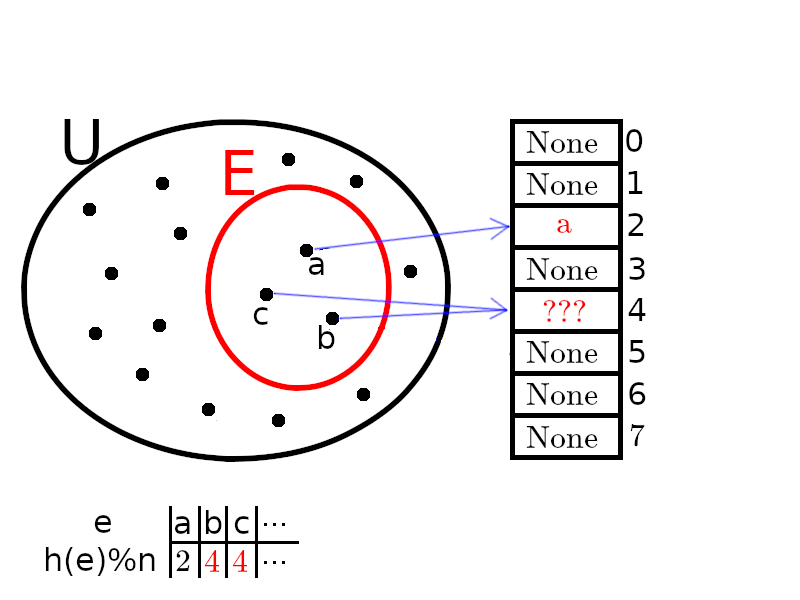
Limiter les collisions
La première chose à faire est de limiter les collisions, en utilisant une fonction de hachage la plus uniforme possible - i.e. minimisant la probabilité de collision de deux clés choisies au hasard. L'application ci-dessus propose de tester plusieurs fonctions de hachage :- l'utilisation du code ASCII de la première lettre (translaté afin que «a» donne 0). C'est une mauvaise idée, certaines premières lettres étant plus communes que d'autres, et cela ne va renvoyer que des valeurs en 0 et 25 (hors première lettree accentuée).
- la somme des codes ASCII des lettres du mot (également translatée). C'est une moins mauvaise idée, mais toujours peu satisfaisant comme le montre le graphique ci-dessous
- la fonction FNV - dont une variante est utilisée pour le codage de la fonction de hachage utilisée par Python. On
part d'un entier $x$ qui va être modifié itérativement
en parcourant les caractères de la chaîne. On fait un
xor(ou exclusif bit à bit) entre la représentation binaire du caractère et celle de $x$, puis on multiplie $x$ par un entier premier (ici $1\,000\,003$). Cette fonction est rapide à calculer, et offre en pratique de bonnes propriétés d'uniformité.
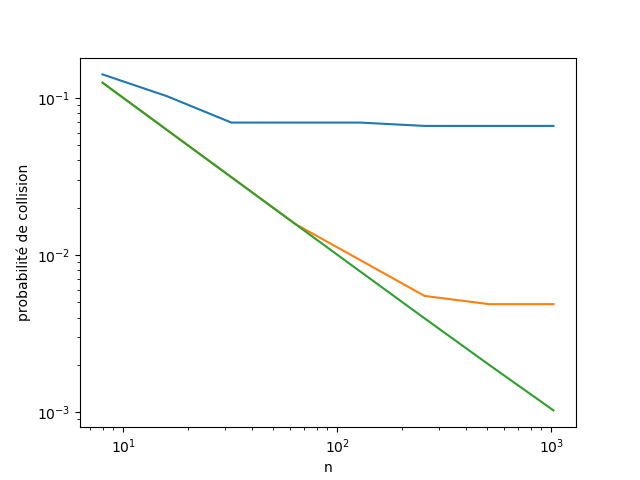
Probabilité de collision pour deux mots du dictionnaire de français choisis aléatoirement en fonction de $n$ pour trois fonctions de hachage : première lettre (bleu), somme des lettres (orange) et FNV (vert).
Dans l'application ci-dessus, vous pouvez visualiser les distributions des clés dans les alvéoles en choisissant une table de taille 128 ou 1024, de type chaînage (expliqué ci-dessous), et en ajoutant de nombreux mots.
Les collisions étant tout de même inévitables, plusieurs mécanismes ont été inventés pour y remédier.
Le chaînage
Chaque alvéole ne contient désormais plus une valeur, mais une liste chaînée de valeurs. On peut donc stocker dans la table de hachage un nombre de clés $m$ plus grand que le nombre d'alvéole $n$. On note $\alpha=\frac{m}{n}$ le taux de remplissage de la table de hachage.On montre alors, sous hypothèse d'une fonction de hachage uniforme, que le nombre moyen de comparaisons effectuées lors d'une recherche qui échoue est de l'ordre de $1+\alpha$ (cf Introduction to Algorithms). Ce nombre est $1+\alpha/2$ pour une recherche réussie.
Adressage ouvert
Autre solution : en cas de collision, on cherche une alvéole libre dans laquelle mettre l'élément à insérer à l'aide d'une méthode de sondage.- Dans un sondage linéaire, on parcourt les alvéoles sucessivement jusqu'à ce qu'on en trouve une vide. On revient au début de la table si la fin a été atteinte.
- Dans un sondage quadratique, si l'alvéole de départ est à l'indice $i$, on cherche une alvéole vide aux indices $(i+1)\%n$, puis $(i+1+2)\%n$, puis $(i+1+2+3)\%n$, etc.
L'algorithme de recherche doit également effectuer un sondage, jusqu'à ce que l'on tombe sur l'élément recherchée ou une alvéole vide. L'algorithme de suppression doit être adapté pour se souvenir qu'une alvéole a été vidée (elle apparaît en bleu avec le mot-clé DUMMY dans l'application), et donc qu'un sondage arrivant dessus doit être poursuivi.
Le sondage linéaire risque de créer des «paquets» d'alvéoles pleines contigües, ce qui peut dégrader les performances des différents algorithmes. En revanche, il permet de gagner sur l'accès au cachepar rapport au sondage quadratique.
Dans tous les cas, l'adressage ouvert ne permet pas de stocker plus d'éléments qu'il y a d'alvéoles dans la table. On peut y remédier en utilisant une approche de type tableau dynamique, où, lorsque le taux de remplissage dépasse une certaine valeur, on créé une nouvelle table de taille plus importante.
En supposant le hachage uniforme, le nombre de comparaisons effectuées lors d'une recherche infructueuse ou d'une insertion est majoré par $\frac{1}{1-\alpha}$.
En Python
Fonctions de hachage
Il existe une fonction de hachagehash pour un certain nombre de types natifs en Python,
notamment les types numériques et les chaînes de
caractères. Les explications qui suivent concernent CPython en
2020 sur une architecture 64 bits. Une valeur de $-1$
signifie une erreur, et si la fonction de hachage doit
théoriquement renvoyer $-1$, elle renvoie $-2$ à la place.
- Pour un entier positif $n$,
hash(n)renvoie $n\%N$, où $N=2^{61}-1$ (qui est premier). - Pour un entier négatif $n$,
hash(n)renvoie-hash(-n) - Pour un rationnel $\frac{p}{q}$ (donc pour un flottant), la valeur renvoyée est
hash(p)hash(q)$^{-1}$, où $x^{-1}$ désigne l'inverse de $x$ dans $\frac{\mathbb{Z}}{N\mathbb{Z}}$. Ceci permet que la fonction de hachage renvoie la même valeur pour un entier s'il est vu comme entier ou flottant, et le calcul est de plus faisable efficacement. Plus de détails ici. Quelques exemples - en gardant en tête que $2^{61}=2305843009213693952$ et $2^{60}=1152921504606846976$. - Pour les chaînes de caractères, une variante de fonction FNV est implémentée (elle utilise notamment une graîne aléatoire qui fera que les valeurs seront différentes d'une exécution à l'autre), ainsi qu'une autre fonction appelée SipHash - offrant de meilleure garantie de sécurité (afin d'éviter des attaques liées à l'utilisation de collisions). Voir le code sourcepour l'implémentation dans CPython des fonctions de hachage, ou cette page pour une discussion sur les aspects liés à la sécurité des fonctions de hachage.
>>> hash(0) 0 >>> hash(1) 1 >>> hash(-1) -2 >>> hash(2**61-2) 2305843009213693950 >>> hash(2**61-1) 0 >>> hash(0.5) 1152921504606846976
__hash__. Pour deux objets égaux au sens de l'égalitée implémentée par __eq__ (celle qui est testée par l'opérateur ==), la fonction de hachage doit renvoyer la même valeur…).
À noter également que des objets mutables tels que les listes ne peuvent être utilisés comme clés : il n'y a donc pas de fonction de hachage pour les listes.
>>> hash([1,2,3]) Traceback (most recent call last): File "", line 1, in TypeError: unhashable type: 'list' >>> s = {[1,2,3]: 4} Traceback (most recent call last): File " ", line 1, in TypeError: unhashable type: 'list'
Ensembles, dictionnaires
Quelques informations rapides sur l'implémentation deset et dict par CPython.
- Le type abstrait «ensemble» est implémenté par le type
set. Elle utilise un adressage ouvert avec un sondage linéaire modifié (pour «sauter» à un autre point du tableau après une petite dizaine d'étapes de sondage purement linéaire permettant de profiter du cache). La taille du tableau est modifiée dynamiquement lorsque le taux de remplissage dépasse $3/5$ (la taille de départ est 8, et est quadruplée ou doublée selon sa taille actuelle). - Le type abstrait «dictionnaire» est implémenté par le type
dict. L'idée générale est expliquée dans cette page : chaque association clé/valeur $k\rightarrow v$ est stockée dans la table des entrées, à un certain indice $i$, et une table de hachage - appelée table des indices contient, dans l'alvéole hash(k), la valeur de l'indice $i$ auxquels sont contenus $k$ et $v$ dans la table des entrées. Cette table des indices est implémentée de façon similaire aux ensembles, avec un doublement de taille lorsque le taux de remplissage atteint 2/3. - Il existe également un type
frozenset, implémentant un ensemble sans possibilité d'ajout ou de suppression d'élément après sa création - ce qui permet quelques optimisations.
Deux exemples d'applications pratiques
- Lorsqu'on implémente un algorithme de parcours d'un graphe dont les sommets ne sont pas tous présents en mémoire au départ mais sont générés au fur et à mesure du parcours, il est nécessaire d'implémenter un ensemble pour se souvenir des sommets déjà rencontrés. Une implémentation efficace utilisant des tables de hachage peut avoir un effet important sur le temps d'exécution de l'algorithme. Cette méthode est par exemple utilisée pour stocker les états rencontrés dans le solveur de taquin.
- Les filtres de Bloomsont une implémentation probabiliste des ensembles,
utilisant de façon centrale la notion de hachage. L'idée est de représenter un ensemble $E$ par une suite de bits longueur fixée $n$ dont le $k$ème bit
vaut 1 si et seulement si il existe $e\in E$
tel que $h(E)\% n = k$. On peut ainsi représenter un ensemble de façon extrèmement compacte, mais on risque d'avoir des faux positifs lors
de la recherche d'un élément $e\notin E$ si
celui-ci est haché sur la même valeur qu'un
élément présent dans $E$.
Les filtres de Bloom sont utilisés dans les bases de données.
Références et liens
- Introduction to Algorithms, de Cormen et al. La bible de l'algorithmique, avec un chapitre consacré aux tables de hachage, qui contient notamment les preuves détaillées des différents résultats donnés ci-dessus.
- Documentation sur l'implémentation du hashage de CPython.
- La fonction FNV.
-
L'implémentation du type
setde CPython. -
L'implémentation du type
dictde CPython.