Cette page démontre une application de l'algorithme des $k$-moyennes à la compression ou au traitement d'images.
Dans une image, la couleur de chaque pixel est typiquement représentée par les niveaux de rouge (R), vert (G - pour Green) et bleu (B). En utilisant la synthèse additive, on peut en effet reconstituer toute autre couleur à partir de ces trois.
Chacun des canaux R, G et B a une valeur comprise entre 0 et 255. Il y a donc $256^3 ≈ 16$ millions de couleurs possibles pour un pixel - et 24 bits sont nécessaires pour coder l'ensemble de ces valeurs (car $2^{24}=256^3$).
Afin de compresser une image, on souhaite par exemple n'utiliser que $k=16$ couleurs différentes - ce qui permettrait de coder la couleur d'un pixel sur 4 bits seulement (car $2^4=16$). Cela réduirait grossièrement d'un facteur 6 la taille de l'image.Cette méthode est par exemple utilisée dans le format d'image bmp. À noter que des méthodes nettement plus sophistiquées sont généralement utilisées pour compresser les images…
La question se pose alors, pour une image donnée, de choisir la palette de 16 valeurs la plus pertinente.
Il s'agit d'un problème de partitionnement de données. Étant donné l'ensemble des couleurs de l'image originale, on souhaite regrouper ces couleurs en 16 paquets - chaque paquet contenant des couleurs proches qui pourront être représentées par une unique couleur «moyenne» dans l'image compressée.
C'est exactement ce que permet l'algorithme des $k$-moyennes. À l'initialisation, une palette de $k$ couleurs est choisie aléatoirement - et chaque pixel est rattaché à la couleur de la palette de laquelle il est le plus proche.
Lors d'une itération, on remplace chaque couleur de la palette par la «moyenne» des couleurs des pixels qui y sont rattachés. On rattache à nouveau chaque pixel à la couleur la plus proche dans la palette.
On poursuit jusqu'à la convergence, c'est-à-dire jusqu'à ce qu'une itération ne modifie plus les couleurs de la palette.
L'application ci-dessous permet de visualiser le déroulement de cet algorithme. Outre l'aspect compression, on pourrait utiliser cet algorithme en traitement d'image pour obtenir des effets d'«à-plat» intéressants.
Itérations : 0 | Score ≈
Palette :
Quelques remarques…
Le score dont il est question dans l'application correspond à la «distance» moyenne de la couleur d'un pixel à la couleur lui correspondant dans la palette. La notion de distance sera précisée ci-après. Ce score décroît à chaque itération, c'est une propriété de l'algorithme des $k$-moyennes.L'importance de l'initialisation
Dans sa version de base, l'algorithme initialise les moyennes à des valeurs aléatoires - chaque moyenne étant tirée uniformément dans l'espace $[0,255]^3$.Chaque exécution sera donc différente de la précédente. Par exemple, si vous lancez plusieurs fois l'algorithme sur l'image «Diagramme teinte-luminosité» avec 4 ou 5 couleurs, vous verrez des résultats différents : il y a quasiment un «plateau» de scores bas - lié au fait que le score ne varie presque pas si l'on fait «tourner» les teintes des couleurs vers la droite ou vers la gauche. L'endroit du plateau auquel l'algorithme va terminer dépend fortement de l'initialisation. Voici par exemple trois configurations finales obtenues pour quatre couleurs.

Vous pouvez également tester l'image «Rumble fish» avec 8 couleurs, et vous observerez que les couleurs rouges et bleues des poissons n'apparaissent pas toujours dans la palette finale. L'algorithme termine ici dans des minima locaux du score, qui ne sont pas nécessairement globaux…
Il existe d'autres façons d'initialiser l'algorithme, ainsi qu'une littérature abondante sur le sujet. Plusieurs méthodes classiques que vous pouvez tester à l'aide de l'application :
- La méthode de Forgy : les moyennes sont tirées au hasard parmi les données - ici parmi les couleurs des pixels de l'image.
- La méthode de Partition Aléatoire : avant de démarrer, on donne une étiquette aléatoire parmi $\{1,\dots k\}$ à chaque pixel de l'image. La moyenne des couleurs des pixels étiquetés par $1$ donne notre première moyenne initiale, la moyenne des couleurs de pixels étiquetés par $2$ donne notre deuxième moyenne initiale, etc. En pratique, cela donne des moyennes très proches et «centrales» par rapport aux données.
- La méthode $k$-moyennes++ est une méthode très efficace en pratique permettant de disperser les moyennes de départ. On choisit la première moyenne aléatoirement parmi les couleurs de l'image, puis successivement les moyennes suivantes parmi les couleurs de l'image avec une probabilité proportionnelle à la distance entre la couleur et la plus proche moyenne déjà calculée. Les nouvelles moyennes ont donc tendance à être choisies «loin» des précédentes.
Distance et moyenne : choix de l'espace des couleurs
L'algorithme des $k$-moyennes fait appel de façon centrale aux notions de «distance» entre deux couleurs, et de «moyenne» d'un ensemble de couleurs (cette dernière se déduisant de celle de distance).Dans la version présentée jusqu'ici, nous nous sommes placés dans l'espace RGB, en considérant que la distance entre deux couleurs $(r_1,g_1,b_1)$ et $(r_2,g_2,b_2)$ était la distance euclidienne dans l'espace $[0,255]^3$ , c'est-à-dire $\sqrt{(r_1-r_2)^2+(g_1-g_2)^2+(b_1-b_2)^2}$.
Que se passe-t-il si nous modifions cette distance, par exemple si nous prenons $\sqrt{(r_1-r_2)^2+(g_1-g_2)^2+(0.3 b_1-0.3 b_2)^2}$ ? Cela revient à dilater l'espace RGB, dans le sens d'une compression de la dimension «bleue» : le bleu aura moins d'importance, et sera plus facilement rapproché d'un gris.
On peut réaliser des modifications plus radicales encore de la distance en se plaçant dans un autre espace de représentation des couleurs, comme l'espace YUV, ou encore l'espace HSV (teinte, saturation, valeur). L'espace HSVPetite difficulté technique sur cet espace : les bords de la composante H se recollent, donnant une espèce de surface cylindrique de dimension 3, sur laquelle la notion de moyenne pose question., si l'on donne une plus grande importance à la composante H, permet de mieux faire ressortir les différences de teintes (rouge, bleu, etc) - au détriment de celles d'«intensité» et de «brillance». Tester par exemple sur l'image «Cheminées» avec 8 couleurs. Ci-dessous des images obtenus à la convergence de l'algorithme appliqué à «Delaunay», en se plaçant dans des espaces de couleurs différents : RGB (en haut à gauche), RGB avec «bleus écrasés» (en haut à droite), HSV (en bas à gauche), HSV où le poids de la composante «teinte» est renforcé (en bas à droite).

C'est un phénomène assez général : le choix de l'espace de description des données a une grande influence sur le comportement et l'efficacité des algorithmes d'apprentissage. Ce choix est très dépendant du problème considéré.
Détermination de $k$
Quel nombre $k$ de couleurs dans la palette choisir ? C'est un problème récurrent avec les algorithmes ayant un paramètre «libre» tel que $k$. Divers éléments sont en balance. Intuitivement :- le temps d'exécution d'une itération de l'algorithme augmente avec $k$;
- dans une optique «compression», celle-ci sera d'autant meilleure que $k$ est petit. Dans les problèmes de classification purs, on préfère généralement avoir un $k$ petit pour modéliser de la façon la plus parcimonieuse possible les données;
- augmenter $k$ permet de mieux approcher l'image de départ.
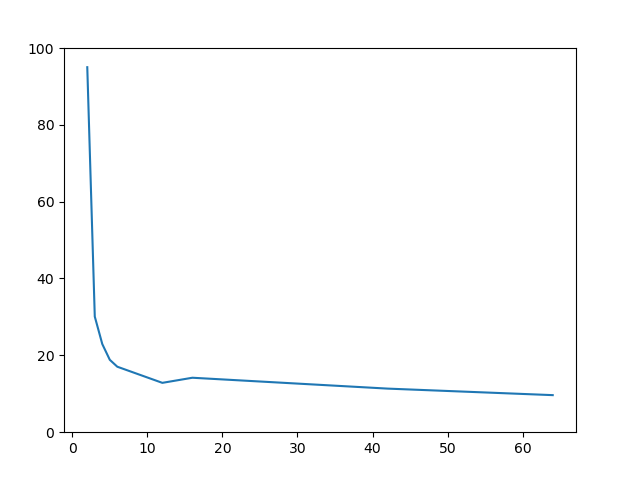
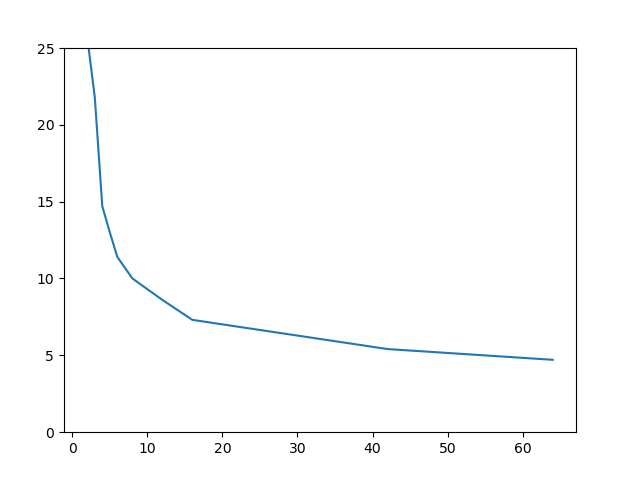
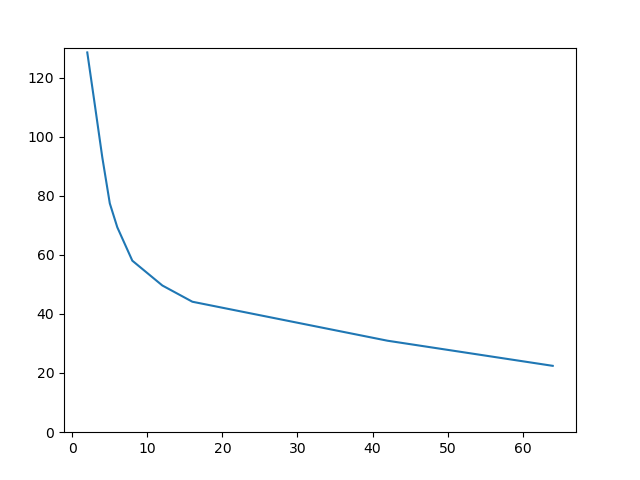
On peut très qualitativement regarder où se situe le «coude» de cette courbe d'apprentissage, au delà duquel augmenter $k$ «n'apporte plus grand chose». Pour l'image «Mondrian», ce coude semble se situer à 4, ce qui est très cohérent avec l'image . Pour «Guépier», plutôt entre 10 et 16. «Diagramme teinte/luminosité» est un cas très particulier : la nature très artificielle de cette image constituée d'un très grand nombre de couleurs dispersées conduit à un coude beaucoup moins marqué : on continue de gagner sur le score lorsqu'on augmente $k$.
Il existe des méthodes plus fines pour évaluer le paramètre $k$, par exemple le tracé de scores de silhouettes.
Courte bibliographie
Pour des approfondissements et liens sur les $k$-moyennes, se référer à la page sur les $k$-moyennes de wikipedia (anglophone). La détermination du paramètre $k$ a sa page wikipedia dédiée. Voir également Machine Learning avec Scikit-Learn, d'Aurélien Géron.Pour aller plus loin sur les algorithmes d'apprentissage :
- Apprentissage machine : De la théorie à la pratique. Concepts fondamentaux en Machine Learning (Massih-Reza Amini)
- Intelligence artificielle 3e édition : Avec plus de 500 exercices (Russel, Norvig)
- Apprentissage statistique (Gérard Dreyfus et al.)












