Exploration de données : l'exemple de la classification de caractères.
Vous venez de découvrir un texte écrit dans un alphabet inconnu, dont voici un extrait.En prenant l'intégralité du texte, on dispose d'un ensemble $E$ de caractères manuscrits (sous forme d'images), et l'on souhaite obtenir l'alphabet dans lequel il est écrit : il s'agit donc de regrouper les images en «paquets» homogènes, chaque paquet correspondant à une lettre de l'alphabet.
Il s'agit d'un problème de partitionnement de données, tel que présenté dans la page des $k$-moyennes.
$k$-moyennes
On peut le résoudre en fixant $k\geq 2$, et en cherchant à trouver grâce à l'algorithme des $k$-moyennes une partition $S_1\dots S_k$ de $E$ minimisant $$\sum_{i=1}^k\sum_{p\in S_i}d(p, m(S_i))^2,$$ où $m(S)$ est la moyenne des points de $S$, et $d(p,q)$ la distance entre deux images $p$ et $q$.Quelle distance choisir ? La première idée, si l'on voit une image de taille $w\times h$ comme un vecteur de $[0,1]^{wh}$ (la couleur d'un pixel étant un élément de $[0,1]$ : 0 pour noir, 1 pour blanc), est de choisir la norme $\mathcal{L}_2$ de la différence entre ces deux vecteurs, i.e. de poser $d(p,q)=\sqrt{\sum_i (p_i-q_i)^2}$, où $p_i$ est l'intensité au pixel $i$ de l'image $p$.
Vous pouvez tester cela avec l'application ci-dessous. Prenez le cas $k=6$ (la valeur voulue théoriquement attendue), une initialisation Forgy ou $k$-moyennes++ (cf la page sur les $k$-moyennes pour des explications), et répétez plusieurs fois l'expérience… pour constater que la partition obtenue est souvent très éloignée de celle qui est attendue.
(Les données sont classées par caractères pour plus de lisibilité, mais on ne connais évidemment pas cette classification a priori !)
Générer des moyennes de départ
Moyennes :
Les mauvais résultats obtenus sont en partie expliqués par la distance que nous avons choisie. Deux images correspondant au même caractère mais pas parfaitement alignées pourraient être à une distance importante l'une de l'autre. Pour améliorer ces résultats, on peut essayer de définir une meilleure définition de la distance : on va pour cela utiliser un descripteur de l'image, c'est-à-dire un vecteur de $\mathbb{R}^N$ pour un certain $N$ «capturant des propriétés intéressantes de l'image». Le choix de ce descripteur est très dépendant du problème, et nécessite une expertise humaine.
Un descripteur classique pour les images est l'histogramme des gradients oriéntés (HOG), qui est un vecteur mesurant les orientations majoritaires des traits dans les différentes régions de l'image.
La distance entre deux images sera alors définie comme la norme $\mathcal{L}_2$ de la différence entre leurs descripteurs. Toute se passe donc comme si nos points initiaux (les images) étaient envoyés dans l'espace des descripteurs dans lequel on applique la méthode de partitionnement - en espérant que les images correspondant aux mêmes caractères soient mieux regroupées dans ce nouvel espace.
Des tests avec l'application montrent que la partition attendue est atteinte pour environ une initialisation sur trois : passer dans l'espace des HOG a fortement augmenté la qualité des solutions trouvées par l'algorithme.
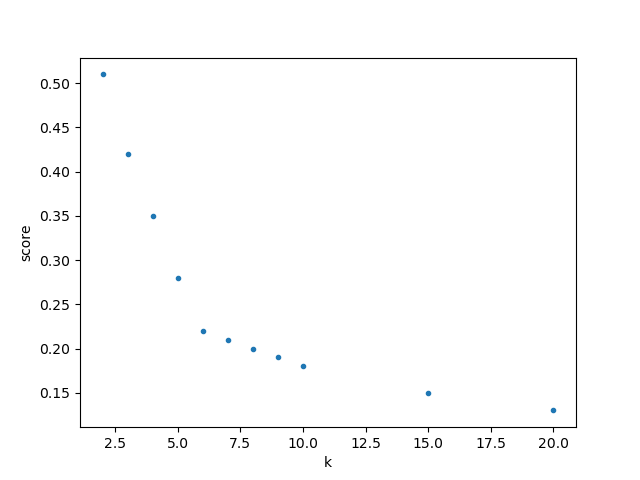
On peut alors regarder l'évolution des meilleurs scores obtenus (sur 20 essais) en fonction de $k$ :
Regroupement hiérarchique
Regroupement hiérarchique désigne une classe de méthodes de classifications de données, qui permet de comprendre et d'organiser des données plus finement qu'à l'aide des $k$-moyennes. Cette page ne traite que de méthodes ascendantes, qui partent des points, et les regroupent pour produire une hiérarchie, qui va être représentée sous forme d'un arbre binaire appelée dendrogramme.Pour ce faire, les points vont être rassemblé dans des groupes, ou clusters.
Regroupement hiérarchique.
- Pour chaque point, créer un cluster contenant uniquement ce point. Chacun de ces clusters est une feuille du dendrogramme.
- Tant qu'il y a au moins deux clusters
- Trouver les deux clusters $C_1$ et $C_2$ les plus «proches»
- Les fusionner pour former un cluster $C$
- Créer dans l'arbre un noeud correspondant à $C$, dont les fils sont les arbres correspondant à $C_1$ et $C_2$
Il existe différentes variantes de cet algorithme selon ce que l'on entend par la distance entre deux clusters. Voici quelques possibilités de notions de distances entre $C_1$ et $C_2$ :
- la distance entre les barycentres de $C_1$ et de $C_2$
- la distance minimale entre $c_1\in C_1$ et $c_2\in C_2$ (Single linkage)
- la distance maximale entre $c_1\in C_1$ et $c_2\in C_2$, dans l'idée de minimiser le diamètre du cluster résultant (Complete linkage)
- la moyenne des distances entre chaque point de $C_1$ et chaque point de $C_2$
- la méthode de Ward propose de considérer la variance du cluster résultant de la fusion de $C_1$ et $C_2$, et donne de très bons résultats en pratique.
On montre que l'algorithme présenté ci-dessus a une complexité temporelle en $O(n^3)$, ce qui le rend difficilement utilisable pour des jeux de données dépassant le millier de points.
L'algorithme des chaînes de plus proches voisins - non-trivial, permet pour certaines des techniques d'agrégation présentées ci-dessus de descendre à $O(n^2)$.
L'application suivante permet, si vous passez la souris sur le dendrogramme, de voir apparaître une «coupe» de celui-ci, et le partitionnement correspondant.
Générer des données : Méthode d'agrégation :
Retour aux caractères
Revenons finalement aux jeux de caractères. Les dendrogrammes permettent de visualiser l'organisation des données, et de comprendre pourquoi le jeu de faux caractères était plus simple à partitionner à l'aide des $k$ moyennes que les chiffres de 0 à 5 ou de 0 à 9.Méthode d'agrégation :








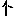
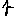
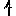
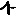
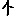
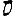
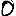

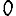







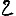
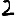
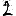
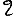
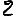
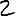
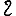
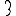
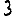
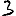
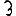
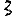
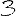
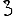
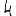
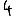
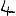

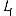
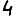
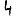
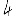
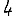
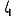
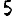
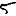
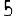
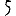
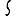
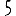
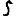
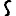
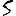
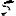
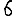
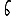
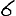
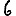
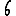
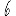

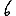
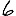
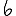
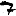
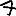
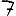
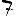
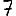
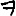
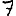
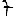
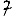
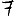
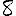
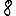
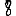
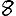
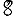
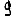
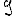
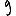
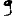
Courte bibliographie
- La page wikipédia des $k$-means contient de nombreux pointeurs vers des algorithmes et problèmes connexes.
- La page wikipedia anglophone du regroupement hiérarchique, qui contient de nombreux liens intéressants.
- Machine Learning avec Scikit-Learn, d'Aurélien Géron.
- Apprentissage machine : De la théorie à la pratique. Concepts fondamentaux en Machine Learning (Massih-Reza Amini)
- Intelligence artificielle 3e édition : Avec plus de 500 exercices (Russel, Norvig)
- Apprentissage statistique (Gérard Dreyfus et al.)