$k$ plus proches voisins
(Cette page s'inspire largement de l'introduction d'Apprentissage statistique (Gérard Dreyfus et al.) - très bonne référence sur le sujet)On dispose d'un ensemble d'«objets», que l'on veut classer en deux catégories (disons rouge ou bleu).
À chaque objet est associé un vecteur de $\mathbb{R}^d$, représentant ses caractéristiques.
On parle de tâche d'apprentissage supervisé lorsque l'on dispose d'exemples d'objets pour lesquels on connaît la catégorie, et que l'on veut, pour un nouvel objet, décider à partir de ces exemples s'il appartient à la catégorie rouge ou bleu. (Pour un exemple de tâche d'apprentissage non-supervisé, voir la page sur les $k$-moyennes.)
La méthode des $k$-plus proches voisins est l'une des méthodes les plus simples pour y parvenir. Étant donné un nouvel objet $O$, on cherche parmi nos exemples les $k$ plus proches (où $k$ est un entier fixé). S'il y a une majorité d'objets rouges parmi eux, on décide que $O$ est rouge, sinon, on décide qu'il est bleu. On choisit $k$ impair afin d'éviter les cas d'égalité.
L'application ci-dessous permet de se familiariser avec cette méthode. On suppose ici que chaque objet est représenté par un point de $\mathbb{R}^2$. Les exemples sont figurés par les points rouges et bleus, dont la position est tirée au hasard selon des lois de probabilités $P_R$ et $P_B$. Lorsque l'on passe la souris sur l'image, les $k$ plus proches voisins du point sous le pointeur de souris sont calculés, et la catégorie de ce point est ainsi déterminée.
La deuxième image est une carte du plan, les zones rouges et bleues correspondant au classement d'un nouvel objet arrivant dans la zone. Les pointillés désignent la frontière «idéale» entre les zones bleues et rouges - nous y reviendrons.
Je vous invite à manipuler l'application pour vous familiariser avec les résultats. En particulier, que peut-on remarquer sur les zones obtenues lorsque l'on fait varier $k$ ?
Erreur d'apprentissage : % | Erreur de généralisation ≈% | Borne théorique ≈%
Matrice de confusion
| R | B | |
|---|---|---|
| R | ||
| B |
Comment déterminer $k$ ?
C'est une question critique, dont va dépendre la qualité des résultats de la méthode. Vous avez du remarquer en manipulant le simulateur que des valeurs «trop grandes» ou «trop petites» ne donnaient pas des résultats satisfaisants.C'est ce que mesure l'erreur de généralisation : pour calculer celle-ci, une fois la carte obtenue, on tire un grand nombre de points selon la loi $P_R$ (i.e. de points qui «devraient» être rouges). On calcule la proportion de ces points qui tombent dans la zone bleue, et l'on fait de même en intervertissant les couleurs. Sur l'exemple ci-dessus par exemple, on obtient ≈% de points mal classés. Étant donné que l'on connaît les distributions $P_R$ et $P_B$ selon lesquelles les points rouges et bleus sont obtenus, il est possible de calculer également la borne théorique i.e. l'erreur qu'obtiendrait un classifieur optimal : il s'agit d'un classifieur bayésien, qui détermine pour chaque point du plan s'il est plus probable qu'il soit obtenu selon la loi $P_R$ (comme point rouge) ou selon la loi $P_B$ (comme point bleu). La frontière de ce classifieur est la ligne pointillée qui apparaît sur la figure.
Naïvement, on pourrait penser choisir le $k$ pour lequel l'erreur de généralisation est la plus petite possible.
Le souci est que, pour un problème réel, nous ne connaissons généralement pas les lois $P_R$ et $P_B$ régissant les positions des points rouges et bleus. Nous n'avons donc pas accès à l'erreur de généralisation (ni à la borne théorique) : nous ne pouvons pas générer de nouveaux exemples de points rouges et bleus pour tester la qualité de notre classifieur.
L'idée suivante est donc, plutôt que de tirer de nouveaux points, de tester la qualité du classifieur sur les points exemples eux-même. C'est la valeur correspondant à l'erreur d'apprentissage ci-dessus. Malheureusement, cela ne fonctionne pas. Si vous testez pour de petites valeurs de $k$, l'erreur d'apprentissage va être petite alors que l'on n'est pas nécessairement à l'optimum d'erreur de généralisation. Dans le cas extrème où $k=1$, tous les exemples sont correctement classés (il sont leur propre plus proche voisin !), alors que le classifieur généralise mal. On parle de phénomène de surraprentissage, ou sur-ajustement.
Les figures ci-dessous montrent des courbes typiques d'erreur d'apprentissage (bleu pour l'erreur de généralisation, rouge pour l'erreur d'apprentissage) en fonction de $k$. Le phénomène de sur-ajustement est visible pour de petites valeurs de $k$, pour lesquelles l'erreur d'apprentissage est très faible, alors que l'erreur de généralisation est grande.
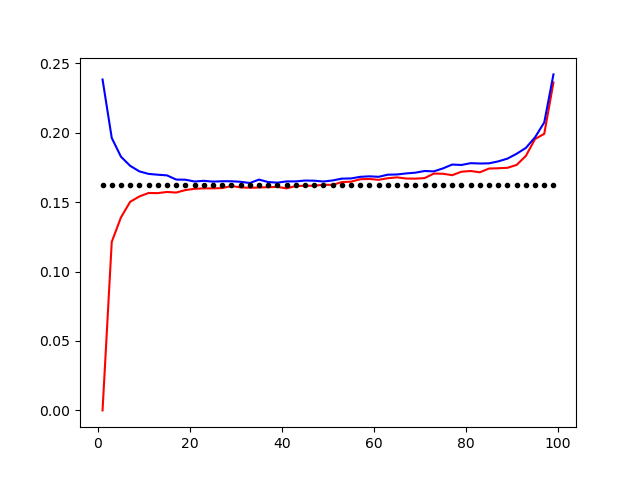
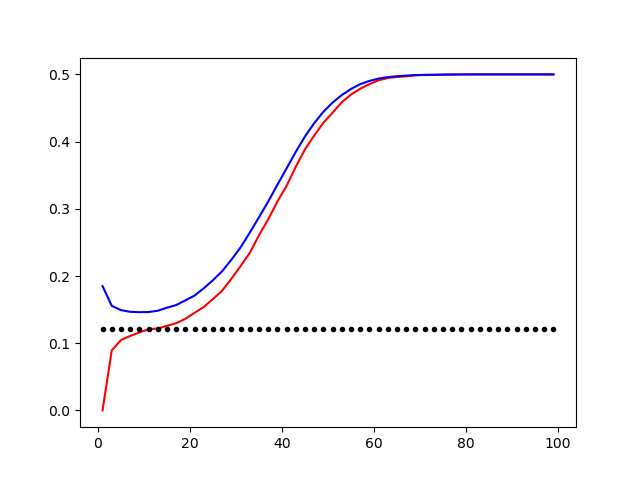
Courbes des taux d'erreur pour les distributions «gaussiennes rapprochées» (à gauche) et «radiales» (à droite). En rouge, l'erreur d'apprentissage. En bleu, l'erreur de généralisation. En pointillés, la borne théorique. On observe un sur-ajustement pour de petites valeurs de $k$.
En pratique, comme on dispose d'un nombre fini d'exemples, une solution est d'utiliser une validation croisée. On partitionne l'ensemble des exemples $\mathcal{E}$ en deux sous-ensembles : $\mathcal{E}_A$ et $\mathcal{E}_T$. On applique la méthode des $k$-moyennes uniquement à l'aide des exemples de $\mathcal{E}_A$ (ensemble d'apprentissage), et on teste la qualité du classifieur obtenu à l'aide des exemples de $\mathcal{E}_T$ (ensemble de test) - ce qui permet d'obtenir une estimation empirique de l'erreur de généralisation, et de déterminer un paramètre $k$ raisonnable. Pour obtenir des résultats plus robustes, on peut répéter l'opération pour de nombreuses partitions $(\mathcal{E}_A, \mathcal{E}_T)$.
Une application à la reconnaissance optique de caractères
On dispose de 400 images (dégradées) de «0», «1», «2» et «3», présentées ci-dessous. Nous allons utiliser la méthode des $k$-voisins (étendue à plus de deux catégories) pour obtenir un classifieur permettant de déterminer à quel chiffre correspond une nouvelle image. Nous choisissons au hasard 96 caractères de chaque type comme exemples pour l'apprentissage (dans $\mathcal{E}_A$), et 4 pour tester la qualité du classifieur obtenu (ils sont donc dans $\mathcal{E}_T$, et sont grisés). La distance entre deux images $I$ et $J$ est définie comme $\sum_{i}(I_{i}-J_{i})^2$, où $i$ parcourt les pixels. Il serait possible de choisir une autre distance, en particulier en redécrivant les données dans un nouvel espace (cf la page sur les SVM où ce type de mécanisme est un peu plus détaillé). On pourrait également débruiter les images.Vous pouvez tester les résultats obtenus pour différents $k$, et changer la pratition $(\mathcal{E}_A,\mathcal{E}_T)$ en cliquant sur «Relancer».
Résultats des tests
| Exemple test |
| 0 | 1 | 2 | 3 | |
|---|---|---|---|---|
| 0 | ||||
| 1 | ||||
| 2 | ||||
| 3 |
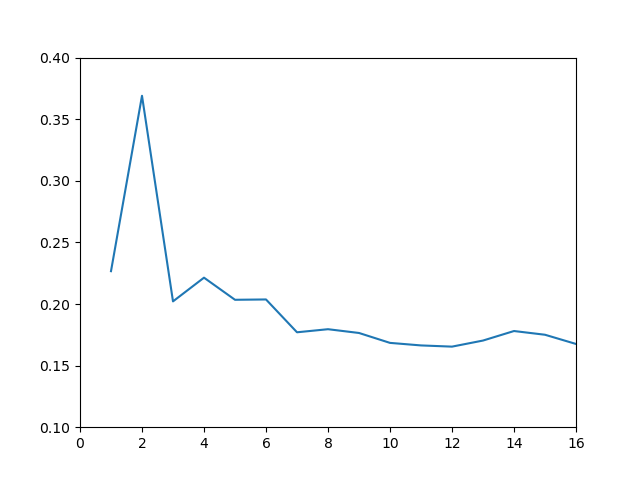
Taux d'erreur empirique en fonction de $k$ pour la
classification de chiffres. Le taux indiqué est obtenue comme moyenne de 4000 expériences de validation croisée utilisant $|\mathcal{E}_A|=4\times 96$ pour l'apprentissage, et $|\mathcal{E}_T|=4\times 4$ exemples pour les tests. (Entre $k=20$ et $k=100$, le taux d'erreur réaugmente très légèrement, de ≈0.16 à ≈0.19)
Les images de chiffres utilisées dans cette page sont disponibles sous forme d'archive.
Aspects algorithmiques
L'un des inconvénients de cette méthode est qu'il est couteux de calculer les $k$ plus proches voisins d'un point. La complexité de l'algorithme naïf est $O(nd)$, où $n$ est le nombre d'exemple utilisés pour l'apprentissage, et $d$ la dimension de l'espace où les données sont décrites. En petite dimension, on peut utiliser des structures du type arbre kd pour accélérer la recherche. Cette page utilise un algorithme de type sweep line partant vers la gauche et vers la droite à partir de l'abscisse du point à classer ainsi qu'un mécanisme permettant d'utiliser les $k$ plus proches voisins du dernier pixel voisin traité pour gagner un peu de temps sur le calcul des cartes. Des arbres kd permettraient certainement d'obtenir ces cartes plus rapidement.D'autre algorithmes, comme les SVM permettent une classification beaucoup plus rapide des nouveaux exemples (en $O(d)$). Les SVM ont de plus de meilleures propriétés de généralisation que les $k$ plus proches voisins.
À noter que la carte dans le cas $k=1$ se déduit du diagramme de Voronoi de l'ensemble des points.
Bref, il y a de l'algorithmique intéressante à creuser pour mettre en place cette méthode.
Courte bibliographie
- Apprentissage statistique (Gérard Dreyfus et al.) pour une introduction à la théorie de l'apprentissage.
- Apprentissage machine, de la théorie à la pratique (Amini) pour pousser un peu plus loin les aspects théoriques.
- THE MNIST DATABASE of handwritten digits (LeCun et al) : une base de données sérieuse de chiffres manuscrits, ainsi qu'une comparaison des résultats de différentes méthods sur cette base.